
 Apecsoft也是一种情怀
Apecsoft也是一种情怀 在 Codex App 中调用本地 Ollama 的 gemma4:e4b 模型时,生成约 4K tokens 后自动停止,其根本原因在于 Ollama 默认的上下文窗口(Context Window)仅为 4096 tokens。
上下文窗口是指模型在一次推理中能够”看到”的最大 token 数量,包括输入提示词(Prompt)和模型生成的输出(Output)的总和。一旦总 token 数达到 4096 的上限,模型就会停止生成,表现为”自动跳出停止运行”。
特别说明:Codex 作为 AI 编程助手,其 Agent 工作流需要处理大量代码上下文,官方建议至少使用 32K-64K 的上下文窗口。因此,突破 4K 限制不仅是解决生成中断问题的需要,更是充分发挥 Codex 能力的必要条件。
第一步 先运行基础模型 gemma4:e4b
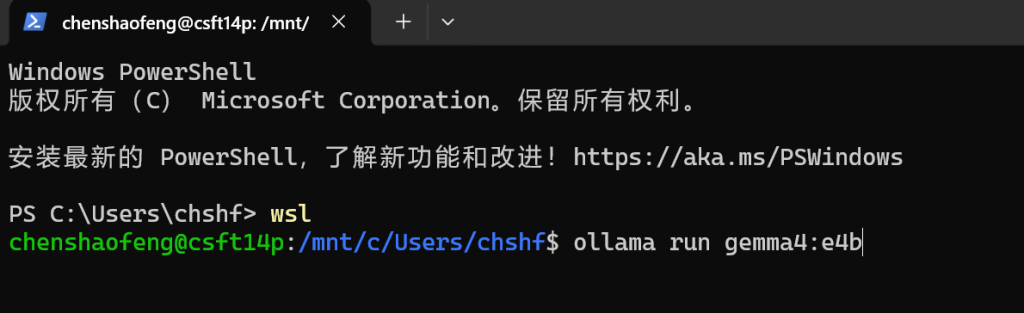
第二步 通过 Modelfile 创建专用模型(最方便有效的方法)
这是最稳定、最推荐的方式。通过创建 Modelfile 定制一个上下文窗口更大的模型版本。官方推荐64K模型是最佳推荐。因为我已经有64K模型了,实际使用中还是有不够用的现象,所以我再创建一个128K的模型,gemma4最大是可以创建256k模型。
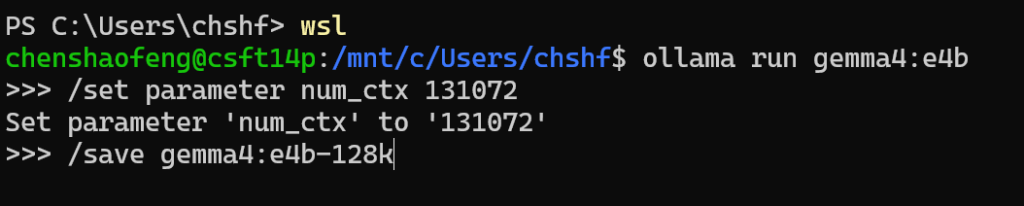
注意这一步必须要在>>>提示符下运行,在出现的 >>> 提示符下,依次输入以下命令
/set parameter num_ctx 131072
/save gemma4:e4b-128k
/bye
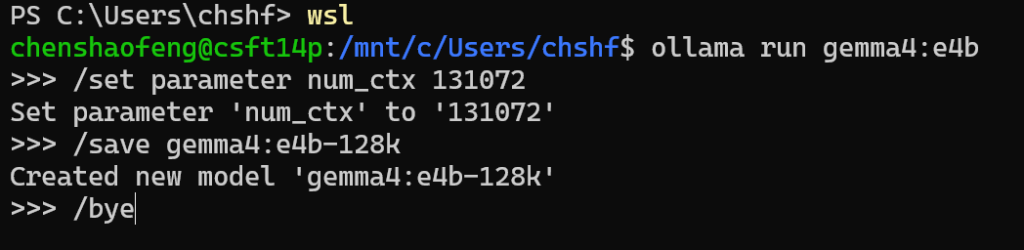
第三步 验证模型
在linux提示符下,用ollama指令启动刚才创建的专用modelfile
ollama run gemma4:e4b-128k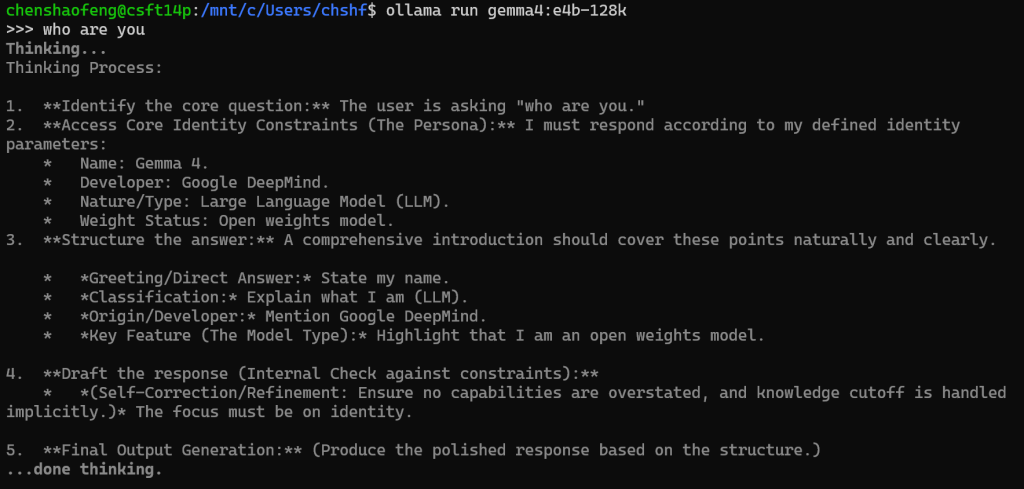
第四步 在codex app中配置对应的上下文窗口参数
返回到winodws,打开codex,进入setting参数配置页面。
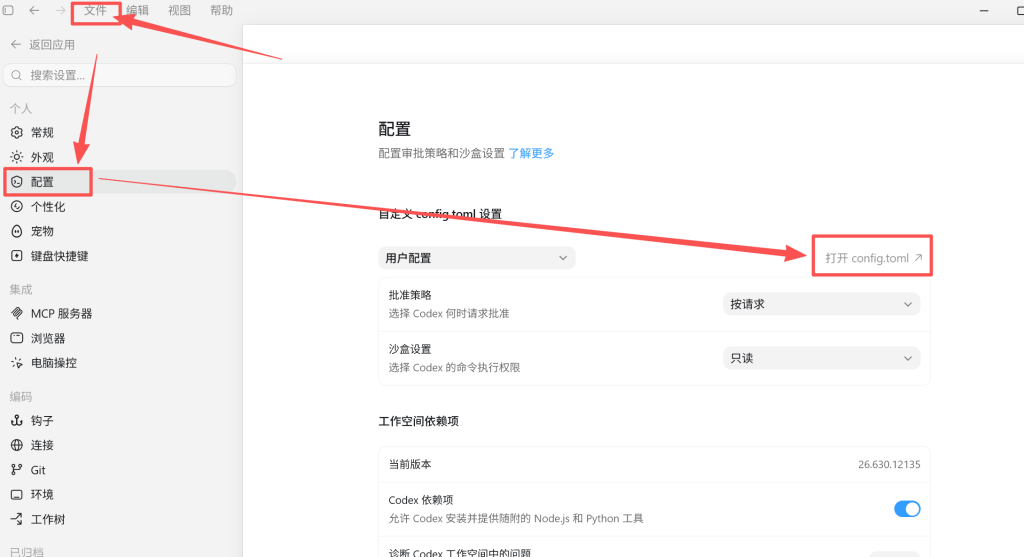
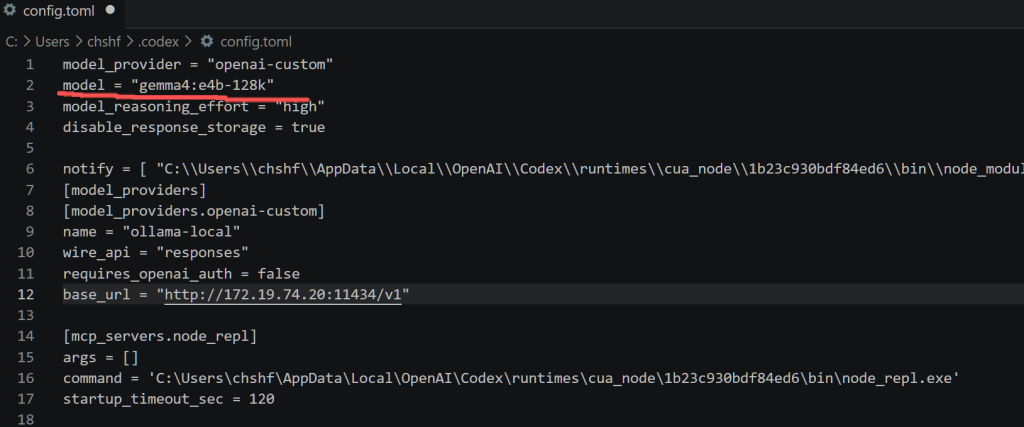
将codex config.toml配置文件的model配置成ollama运行的专用模型名称,这样就将上下文窗口限制改为128K。
以上就是我在试验用codex桌面端接入wsl2 ubuntu系统下ollma各种模型的实际经验汇总。适合小白用户,可以避坑节省时间。
到现在实际测试了qwen2.5:7b, qwen3.5:9b, gemma4:e4b, 在32GB内存无独显笔记本上使用,gemma4表现最强,强烈推荐。
未经允许不得转载:阿帕克软件-Apecsoft » Codex调用本地 Ollama gemma4:e4b 模型突破 4K 上下文限制经验总结
